Fatigue detection using machine learning
The peloton profoundly molded and shaped the design of the Bike+ app.
My experience training and preparing to race the 2004 racing season in support of Chris Horner and Charles Dionne lead me to think deeply about endurance, stamina, and fatigue in the late winter of 2003. My role on the team was going to be to support Chris and Charles as long as possible, keeping them tucked out of the wind near the front of the peloton. Any day that Chris or Charles had a leader’s jersey at a race, I might have to tow the peloton in my wake all day in defense of their jersey. Throughout the winter I was laser-focused on improving my endurance and stamina. I needed to push out the point in time where I fatigued so I could help Chris and Charles out as deep into the race finale as possible. This train of thought steered me to ponder if I could develop and algorithm to automatically detect the point of fatigue in physiological data.
The week prior to the 2004 Redlands stage race, I sketched out some of these ideas in a series of notes.

Initial notes on fatigue detection algorithm from March 2004
These notes sketched out a caveman-like approach to detecting fatigue. The concept described in the notes was to compare the average power for the workout to a ten minute rolling average of power for the workout. At the beginning of the workout, the ten minute rolling average should be higher than average power. As the workout continues, and you fatigue, the recent, ten minute rolling average power will decrease and eventually fall below the average power for the entire workout. The time where crossing point occurs is the fatigue point. These notes also describe a concept for hydration and energy consumption alarms, which eventually found their way into new World Champ Tech workout apps.
At the time, the only real power meter option available in the peloton was the SRM Power Meter. I raced and trained with an SRM, but the steep, $4,000 price tag, limited access to the SRM (this was several years prior to the expiration of the SRM patents and the release of the Quarq Power Meter). I thought that perhaps at some point in the future it would be possible to create a substitute head unit to replace the SRM Power Control, and that I could incorporate these algorithms into a device (note that it would be another three years before the Garmin Edge 605/705 models were released with ANT+ connectivity). But, developing my own head unit seemed like it would be an extremely capital-intensive effort to target a relatively modest market, and unlikely to succeed.

My red SRM Power Control is visible as I lead my teammate Chris Horner at the March 2004 Merced Criterium
Thankfully, technology slowly advanced. ANT+ was introduced in 2004 to allow for wireless transmission of fitness data, with the first ANT+ compatible devices arriving to the market in 2007. Bluetooth Low Energy (BLE) was released in 2009, but it wasn’t until 2017 that Quarq and SRM released BLE compatible power meters. The Apple iPhone has supported BLE since the iPhone 4s, which was released in 2011, but without power meters transmitting data via BLE, it wasn’t possible to use the power of an iPhone to process this data. And, the processing power of the iPhone was exploding. The processing performance of the current top-of-the-line iPhone 15 Pro is nearly 250 times greater than the iPhone 3GS released back in 2009. The Apple Watch - though not nearly as fast as the iPhone - has seen a similar acceleration in computing performance since its launch in 2015.
The summer of 2017 formed a convergence point. Apple announced the release of a new software framework for iOS and WatchOS dedicated to machine learning and artificial intelligence - CoreML, or Core Machine Learning. BLE power meters had recently hit the market, and the Apple Watch was rapidly improving to become a tiny, wrist-mounted supercomputer. A period of experimentation with the CoreML framework inspired me to revisit my fatigue detection notes, and try to apply machine learning to the fatigue detection problem. But, my experiments with CoreML also showed me that it lacked the flexibility I needed, so I would have to develop my own custom solution.
ChatGPT has garnered headlines as the most advanced machine learning based AI system in the world today. Linear regression is the opposite: the most primitive machine learning technology. But, despite the neanderthal-nature of linear regression, it seemed well suited to the problem of fatigue detection. As an athlete exercises, there is a linear relationship between the individual’s heart rate and their effort, or power level, up to the point where they reach their maximal oxygen usage. Eventually though, as the athlete fatigues, this linear relationship breaks down. As the athlete attempts to go hard, the point where they transition from primarily aerobic metabolism to anaerobic metabolism to satisfy their energy requirements shifts downward. Linear regression is a useful machine learning technology for detecting when the athlete fatigues and their heart rate to power relationship starts to drift away from this nice linear relationship.
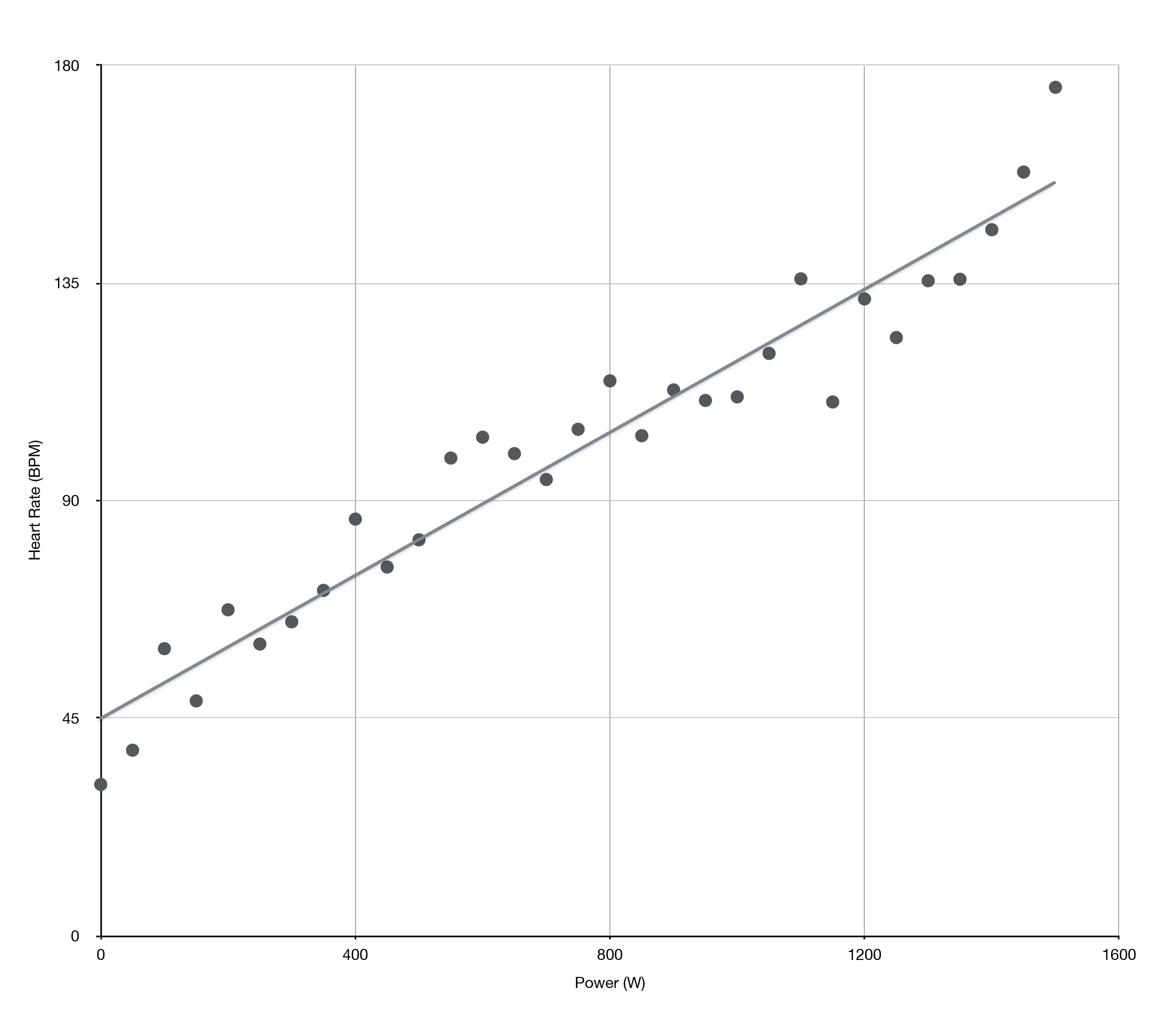
Heart rate has a linear relationship to power or effort
A simple, and perhaps naive, approach to detecting fatigue would be to create to boundaries around the linear relationship between heart rate and power based on the standard deviation, or variance, using standard statistical tests such as the t-test. Any points outside these bounds could potentially indicate fatigue. Now, there are alternative explanations other than fatigue for why an athlete’s heart rate doesn’t correspond as expected based on their current power output or effort level. Heart rate doesn’t adjust immediately when you increase or decease your effort. So, its possible that a data point with high power output, yet a low heart rate measurement is indicative of the rider at the start of a hard effort before their heart rate has adjusted to the increased power output, instead of showing signs of fatigue.
Part of the solution to this issue is to smooth the power and heart rate values using some form of moving average technique. Heart rate tends to adjust to an effort after 30-60 seconds. Smoothing over a longer time period - such as two to four minutes - can help eliminate the artifacts in the data at the start of a hard effort such as an interval. Smoothing can also help eliminate the occasional low quality heart rate measurement from chest-based heart rate monitors that detect the electrical activity of the heart when external electrical signals from power lines or other sources of electrical noise interfere with the measurement.

Naive confidence bounds around linear regression between heart rate and power
But, using linear boundaries around the regression line is quite naive, and only works if you are certain of the error variance, which seldom holds in practice. Instead, the forecast error variance should be used, which leads to parabolic boundaries surrounding the recession line with the vertex of each boundary centered at the mean, or average, value of the data points. The standard deviation of the data points will control the shape and curvature of the parabolic boundary with a larger standard deviation leading to increased curvature.

Parabolic confidence bounds for estimated linear regression slope and intercept
Points in the region above the regression line have a different interpretation than points below the regression line. Below the regression line, heart rate fails to respond as expected to the given power output from the athlete, and does not rise as much as expected. This occurs as an athlete fatigues. The rate at which heart rate changes to changes in work load or power output drops. Points below the regression line occur when heart rate is lower than expected for a given power output when the individual has increased their work load. Points above the line have two separate interpretations. These points can be observed when an individual decreases their power output, but heart rate doesn’t drop as much as predicted by the linear regression. However, these points can also occur in high temperatures due to cardiac drift. The body uses blood to transport heat from the core to the skin surface where it by sweat evaporation and the convective cooling effects of airflow past the individual. The heart beats faster in hot environments to transport heat away from the core as the individuals’ core temperature rises from exercise. You will observe data points with higher than expected heart rates for a given power output in these conditions.

Fatigue and heart rate thermal drift zones
The Bike+ app - along with the other World Champ Tech workout apps - employs this algorithm to detect both type of fatigue signals. Data points in the fatigue zone or the heart rate thermal drift zone both indicate possible fatigue. When the algorithm detects one of these points, it presents an alert gently nudging the athlete to consider slowing down, or reducing their work load, to minimize the chance of injury during the workout, as well as to better recover and adapt to the training load in preparation for their next workout.

Data points outside of confidence bounds indicate possible fatigue
World Champ Tech has applied for a patent on elements of this novel technique - patent application number 17/565,909, “System and Method for Real Time Machine Learning Model Training and Prediction Using Physiological Data.”
— James